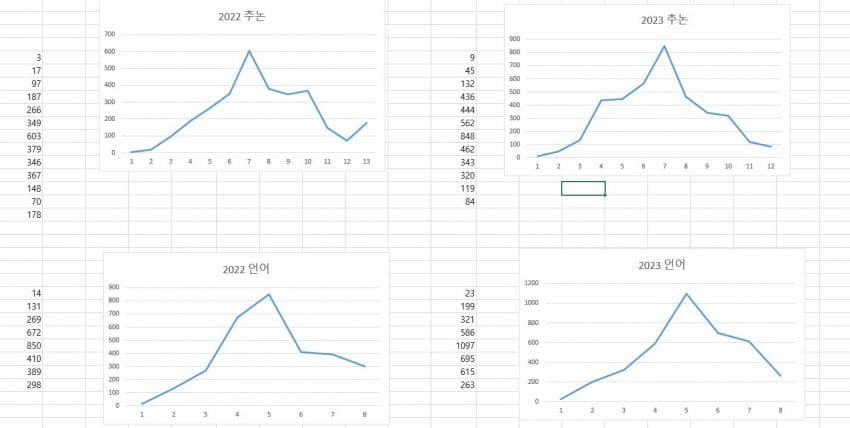
위에 사진은 단순히 법저 표본 나온 거 엑셀에 써서 분포 그린거임.
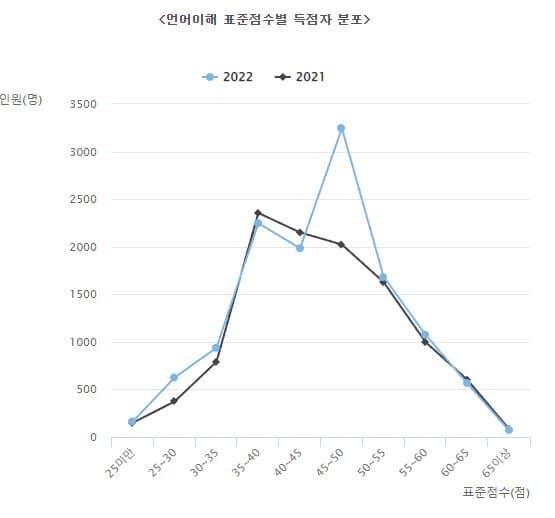
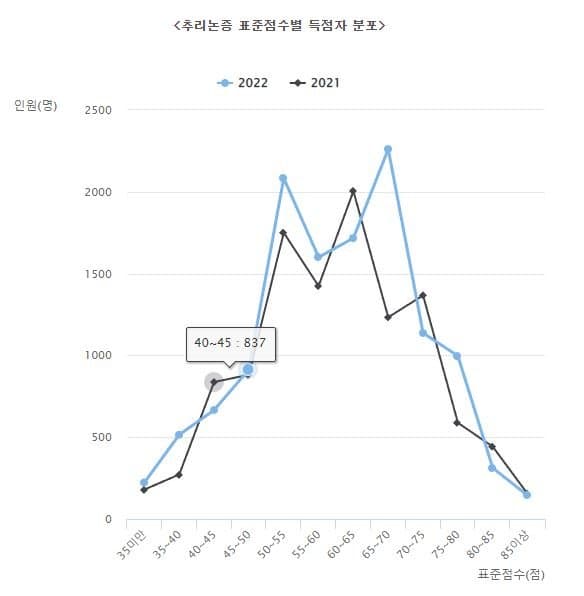
아래 두 사진은 메가로스쿨 가서 그냥 캡처한 실제 표본 분포임.
미안하게도 윗 사진은 좌우 반전을 해야됨. (즉, 윗 사진은 왼쪽부터 표점 높은 순이고 아래는 왼쪽부터 낮은 순임)
간단히 해석을 하자면,
2023 언어이해은 2021 분산과 비슷한 형태고
2023 추리논증은 2021을 뒤집어놓은 형태임.
이러면 어떻게 되냐.
2023 언어이해의 경우 2021 언어이해 표준편차를 따라가고,
2023 추리논증은 2022 추리논증보다 표준편차가 낮게 잡히게 될 것임. (표준편차 기준 2021> 2022)
그렇기 때문에 법률저널 추정은 엉터리라고 할 수 있음.
평균 대충 높게 추정해서 작년 표준편차 집어넣은 것 같은데 개인적으로는 그렇게 할 거면 그냥 지나가는 초등학생 붙잡고 해도 될듯.
결론을 좋아하는 친구들을 위해 말하자면 실제 표점은 법률저널 표점보다 훨씬 높게 형성될 확률이 높음.